J'ai travaillé à la conception d'un serveur de fichiers qui pourrait décharger le site Web principal et servir les images/fichiers sur le Web au client.Approches de conception de serveur de fichiers
Les principaux objectifs du serveur de fichiers:
- Enlever la charge du serveur principal qui héberge le site
- Réutiliser la base de code du serveur Web existant et éviter la duplication de code/logique pour une meilleure maintenabilité
- être évolutive pour augmenter téléchargements
- Masquer le chemin d'accès de téléchargement réel de l'utilisateur
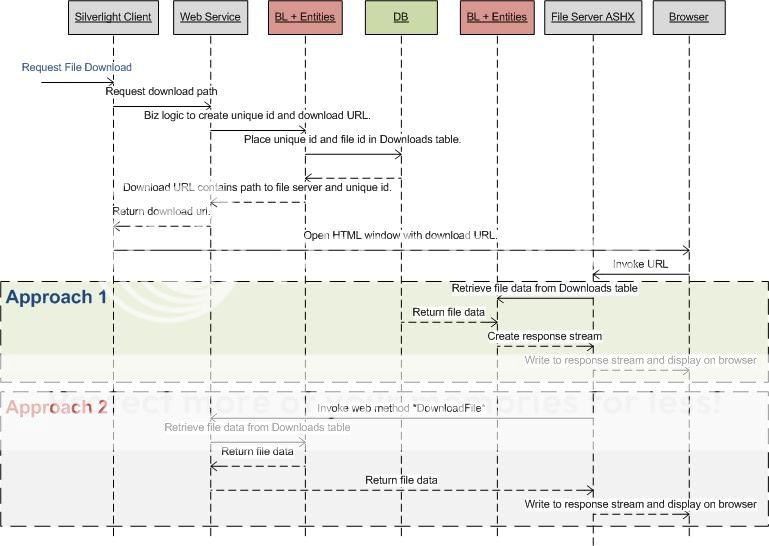
En gardant ci-dessus à l'esprit, je pourrais proposer deux approches. Diagramme de séquence représentation des deux approches pour faciliter la compréhension [des excuses pour l'utilisation asymétrique du diagramme de séquence]. Aucune de ces approches ne satisferait tous mes objectifs.
Laquelle de ces approches recommanderiez-vous pour atteindre mes objectifs?
Y a-t-il une meilleure troisième approche?
Certaines différences, je pouvais penser:
- Approche # 1 conduirait à dupliquer le code BL provoquant maintenabilité émet
- Approche # 2 serait la réutilisation du code et centraliser BL réduire maintenabilité émet
- Approche # 1 réduirait les appels réseau tandis que # 2 les augmente
Le concept de serveurs de fichiers, l'évolutivité des téléchargements, la distribution de la bande passante ont tous été là depuis un moment maintenant. S'il vous plaît partagez vos pensées!
MISE À JOUR:
Approche # 1 semble très attrayante car elle prend la charge hors du serveur principal complètement. Le seul problème à résoudre dans # 1 est les problèmes de duplication de code et de maintenabilité. Cela pourrait être surmonté en ayant un seul projet pour BL/DAC comprenant la fonctionnalité requise à la fois par le service Web et le serveur de fichiers. Et référencez l'assembly/bibliothèque dans les projets de service Web et de serveur de fichiers. Maintenant, il n'y a qu'un seul code BL/DAC à maintenir et évite également les appels réseau dans l'approche # 2.
{kind=link}
@Jaimal: Par fichiers, je veux dire les documents stockés sur le serveur web/db qui ont été téléchargés par l'utilisateur. L'objectif est de le rendre évolutif plus tard pour héberger sur un centre de données. – pencilslate
@Pencilslate: Hmm, lors du téléchargement, réécrire le nom du fichier avec un guid rendant l'url difficile à lire et une URL unique à 99,99%, écrire le fichier sur un serveur séparé. Stockez le guidas votre colonne indexée dans un db avec d'autres méta-données (taille de nom de fichier, type date de téléchargement etc etc.). Ensuite, lorsque le fichier est demandé, prenez le fichier en utilisant le guid.Vous pouvez rapidement réécrire le nom de fichier à son original lors de l'envoi du flux de réponses. Vous avez donc déjà créé votre nom de fichier unique et donc unique d/l url et ne devez pas en créer un au moment de la demande. –