J'essaie de gratter un prix à partir d'une page Web en utilisant PHP et Regexes. Le prix sera au format £ 123,12 ou $ 123,12 (c'est-à-dire, livres ou dollars).Grattez un prix sur un site Web
Je charge le contenu en utilisant libcurl. La sortie de ce qui va ensuite dans preg_match_all. Donc, il ressemble un peu à ceci:
$contents = curl_exec($curl);
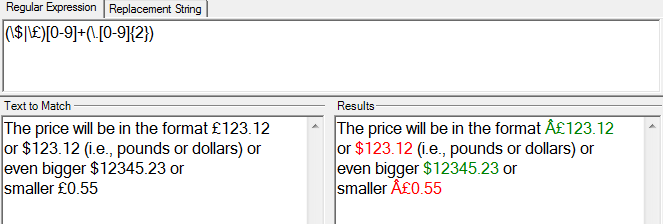
preg_match_all('/(?:\$|£)[0-9]+(?:\.[0-9]{2})?/', $contents, $matches);
Jusqu'ici si simple. Le problème est que PHP ne correspond à rien - même s'il y a des prix sur la page. Je l'ai réduit à un problème avec le caractère '£' - PHP ne semble pas aimer ça. Je pense que cela pourrait être un problème de charset. Mais quoi que je fasse, je n'arrive pas à trouver PHP pour le faire correspondre! Quelqu'un a des idées?
(Edit: Je dois signaler si j'essayer d'utiliser le Regex Test Tool en utilisant la même regex et contenu de la page, il fonctionne très bien)
{kind=link}
Ne fonctionne pas, malheureusement :( –
J'ai modifié la regex et supprimé quelques autres choses.Vérifiez la capture d'écran.Etes-vous sûr que ce n'est pas la façon dont vous utilisez la correspondance après la regex? –
Je viens de remarquer votre modification. le regex fonctionne bien il pourrait être l'encodage de la page de la boucle qui vous donne un problème d'encodage avec $ et £ Vous pourriez vouloir sortir les données de boucle pour le vérifier –