1
Bonjour, je fais peu de recherche sur le système de fichiers Hadoopnoms de fichiers Hadoop emplacement
Je cherche ce point:
- Hadoop emplacement transparent noms de fichiers, ou l'emplacement indépendant?
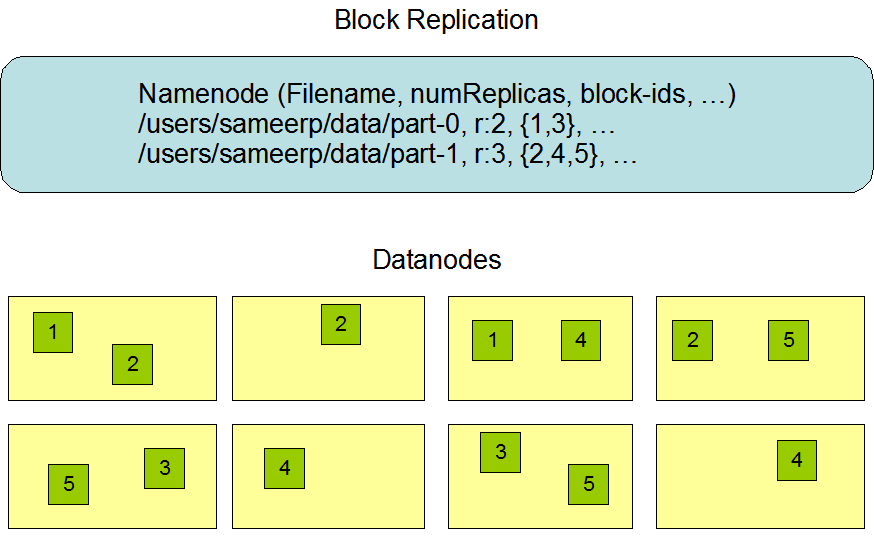
- Comment la réplication est-elle effectuée dans Hadoop et comment la cohérence est-elle maintenue?
Tout expert avec Hadoop peut donner quelques détails
{kind=link}
Nous vous remercions de votre aide. –