http://farm8.staticflickr.com/7020/6702134377_cf70482470_z.jpgfichiers EC2, Mettre en ligne sur premier à volume ebs puis de passer à s3
{kind=link}
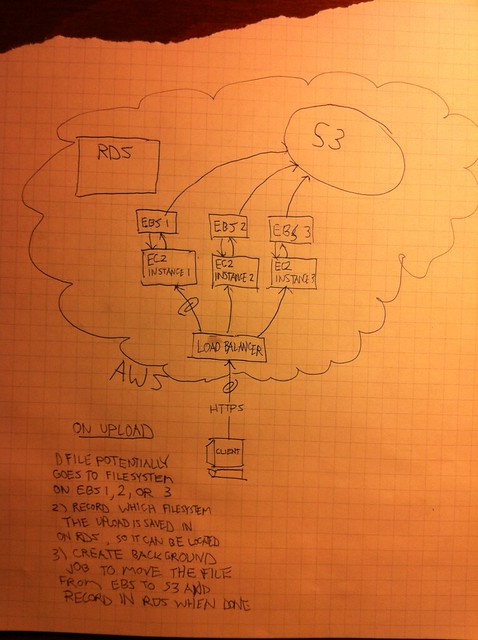
OK désolé pour le terrible dessin, mais il semblait une meilleure façon d'organiser mes pensées et de les transmettre. J'ai lutté pendant un certain temps avec la façon de créer un système découplable facilement adaptable pour télécharger des fichiers sur une application web sur AWS.
Le téléchargement directement vers S3 fonctionnerait sauf pour le fait que les fichiers doivent être immédiatement accessibles au téléchargeur pour la manipulation puis une fois manipulés, ils peuvent aller à s3 où ils seront servis à toutes les instances. J'ai joué avec l'idée de créer un SAN avec quelque chose comme glusterfs, puis de le télécharger directement sur celui-ci et de servir à partir de cela. Je ne l'ai pas écarté, mais de diverses sources la fiabilité de cette solution pourrait être moins qu'idéale (si quelqu'un a un meilleur aperçu sur ce que j'aimerais entendre). En tout cas je voulais formuler une solution plus "out of the box" (dans le contexte d'AWS). Donc, pour développer ce diagramme, je veux que le fichier soit téléchargé sur le système de fichiers local de l'instance vers laquelle il va, qui est un volume EBS. L'emplacement de stockage du fichier ne serait pas diffusé au public (c'est-à-dire/tmp/uploads /) L'instance pouvait toujours accéder à l'instance via une opération readfile() en PHP afin que l'utilisateur puisse la voir et la manipuler immédiatement après le téléchargement. Une fois que l'utilisateur a fini de manipuler le fichier, un message pour le déplacer vers s3 pourrait être mis en file d'attente dans SQS. Ma question est alors une fois que j'ai sauvegarder le fichier "localement" sur l'instance (qui pourrait être n'importe quelle instance due à l'équilibreur de charge), comment puis-je enregistrer sur quelle instance il se trouve (dans la DB) grâce à PHP pour lire ou déplacer le fichier va trouver ledit fichier.
Si quelqu'un ayant plus d'expérience dans ce domaine a un aperçu, je serais très reconnaissant. Merci.
Oui c'est bien la solution que j'ai trouvée (la première n'est pas les sessions collantes). Je l'aime parce qu'il prend la charge de téléchargement sur les instances EC2.Le transfert entre EC2 et S3 est très rapide donc ça marche plutôt bien. – Henry