2
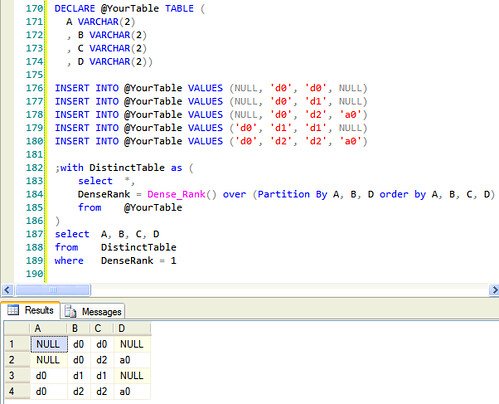
J'ai une requête qui renvoie un jeu de résultats similaire à celui ci-dessous (en réalité, il est beaucoup plus, des milliers de lignes):éliminer les lignes en double partielles de jeu de résultats
A | B | C | D
-----|----|----|-----
1 NULL | d0 | d0 | NULL
2 NULL | d0 | d1 | NULL
3 NULL | d0 | d2 | a0
4 d0 | d1 | d1 | NULL
5 d0 | d2 | d2 | a0
Deux des lignes sont considérées duplique, 1 et 2, car A, B et D sont identiques. Pour éliminer cela, je pourrais utiliser SELECT DISTINCT A, B, D, mais je n'obtiens pas la colonne C dans mon jeu de résultats. La colonne C est nécessaire pour les lignes d'information 3, 4 et 5.
Alors, comment puis-je viens de l'ensemble des résultats ci-dessus à celui-ci (le résultat apparaissant en C4 peut aussi être NULL au lieu de d1):
A | B | C | D
-----|----|------|-----
1 NULL | d0 | NULL | NULL
3 NULL | d0 | d2 | a0
4 d0 | d1 | d1 | NULL
5 d0 | d2 | d2 | a0
A, B et D sont des colonnes qui définissent unicité? – gbn
Et la colonne C peut être ignorée pour les doublons? – gbn